LSTM Models and Portfolio Risk: How Sequence Models Strengthen Allocation

- Mean-variance optimization fails under stress because it treats correlations as fixed and static.
- LSTMs capture how risk evolves over time, filling gaps MPT was never designed to handle.
- Out-of-sample studies show LSTM-enriched portfolios can improve Sharpe ratios by up to 18%.
- Walk-forward validation is non-negotiable; without it, results rarely survive live trading.
- Transformers offer marginal accuracy gains over LSTMs but at significantly higher computational cost.
Modern Portfolio Theory has shaped asset allocation for decades. It offered a clean, mathematical framework for balancing risk and return, and for many years it worked well enough. But anyone managing portfolios today knows the landscape has changed.
Markets react faster, relationships shift more frequently, and risk often behaves in non-linear ways that a strictly linear optimizer like Mean Variance Optimization (MVO) simply cannot capture.
Most quants eventually run into the same limitation. MVO relies on a single covariance snapshot and assumes the world remains stable. It treats risk as a static structure, even though correlations expand and collapse depending on the regime. When volatility spikes or liquidity thins, traditional optimization often produces results that look elegant on paper but struggle in live trading. These are not theoretical complaints they are practical issues you see the moment you attempt dynamic allocation in a real portfolio.
This is where sequence-driven models such as Long Short-Term Memory networks can offer genuine value. LSTMs do not replace financial theory; they add another layer of understanding. By modeling how risk evolves through time and by learning non-linear dependencies, they help fill in the missing dynamics that MPT was never designed to handle.
If you work with financial data pipelines, a Power BI tutor can help you visualize portfolio metrics and model outputs more effectively. In 2026, a growing body of peer-reviewed research from Annals of Operations Research, ScienceDirect, and IEEE confirms what many practitioners have been observing in backtests: LSTM-enriched allocation pipelines consistently outperform classical benchmarks when combined with rigorous out-of-sample validation. This article explains why that is, how to build it, and what its real limits are.
Get Personalized Online Tutoring
Where Does MPT Break Down in Practice?
Mean-variance optimization breaks down primarily because it treats the world as static fixed correlations, stable return distributions, and a covariance matrix that perfectly describes tomorrow using only yesterday’s snapshot. Real markets do none of these things.
Three failure points appear immediately in live data.
The Linear Covariance Assumption Collapses Under Stress
Financial correlations are not stable. Equity and credit correlations rise sharply during drawdowns, while FX and rates may behave differently across regimes. MVO treats correlations as linear and fixed, which means it often understates risk during expansion periods and overstates diversification benefits during genuine stress precisely when accurate risk measurement matters most.
Some engineers argue this can be fixed with rolling windows. This is true under conditions, but it remains a reaction mechanism, not a predictive one. The optimizer still has no forward memory.
Temporal Instability Is Structural, Not Incidental
The covariance matrix is only a snapshot. If markets transition from low to high volatility, the optimizer has no awareness of recent changes. It does not “remember” the conditions that led to the current state.
As Dr Thomas Starke, faculty for QuantInsti’s Executive Programme in Algorithmic Trading, has repeatedly noted, ignoring the path of returns removes information that could meaningfully strengthen allocation decisions.
Estimation Error Compounds Everything Else
Even with large datasets, covariance matrices are notoriously noisy. A small change in estimated inputs leads to disproportionate changes in weight allocations. This is sometimes called Markowitz’s curse: the optimizer is highly sensitive to the very inputs it depends on.
HRP (Hierarchical Risk Parity), developed by Marcos López de Prado in 2016, was designed specifically to address this; it never inverts the covariance matrix and therefore avoids the instability that plagues MVO when inputs are noisy. Students studying quantitative methods may also find that an industrial engineering tutor can provide useful grounding in optimization frameworks that underpin these allocation models.
To understand why modern markets challenge traditional theory, let us compare the static approach of MPT with the dynamic nature of LSTMs.

Static models like MPT take a snapshot of risk, while LSTMs analyze the entire movie of market behavior. These issues compound in environments where relationships shift quickly which is now the norm rather than the exception.
The Ultimate Guide to Online Tutoring 2026: Expert Tips, Pricing & Platform Reviews
How Do LSTMs Provide Temporal Awareness and Non-Linear Insight?
LSTMs are a subclass of recurrent neural networks designed to work with sequences. What makes them useful in finance is not magic but structure: they maintain information over longer time horizons through three learned gates input, forget, and output allowing them to capture how returns, volatility, and correlations evolve rather than just averaging them.
A published framework from Annals of Operations Research (February 2026) combining LSTM-based return forecasting with fuzzy clustering and dynamic optimization demonstrated that this integrated approach “significantly outperforms benchmark approaches across portfolio performance metrics” on Nasdaq data spanning 2017 to 2024. The key mechanism: LSTM improved the upstream signal quality before the optimizer ever ran, which is the correct architecture.
LSTMs are not a direct replacement for an optimizer. Instead, they enhance the upstream information feeding into the allocation process. Two areas are particularly important.
Forecasting inputs that are hard to model linearly. In many portfolio systems, expected returns come from predictive signals. An LSTM can refine these signals by learning shifts in volatility regimes, correlation breakdowns, momentum decay and reacceleration, and macro-driven changes in risk premia.
Even modest improvements in forecasting translate into better weight decisions downstream. This integration of predicted insights into position sizing is one of the reasons machine learning in portfolio management is gaining traction among quants. For those building financial models and reports, guidance on essay writing can also help communicate quantitative findings clearly to non-technical stakeholders.
This integration is not about replacing the optimizer, but enhancing the fuel it runs on. The flowchart below illustrates exactly how the LSTM engine processes data before it ever reaches the allocation stage.
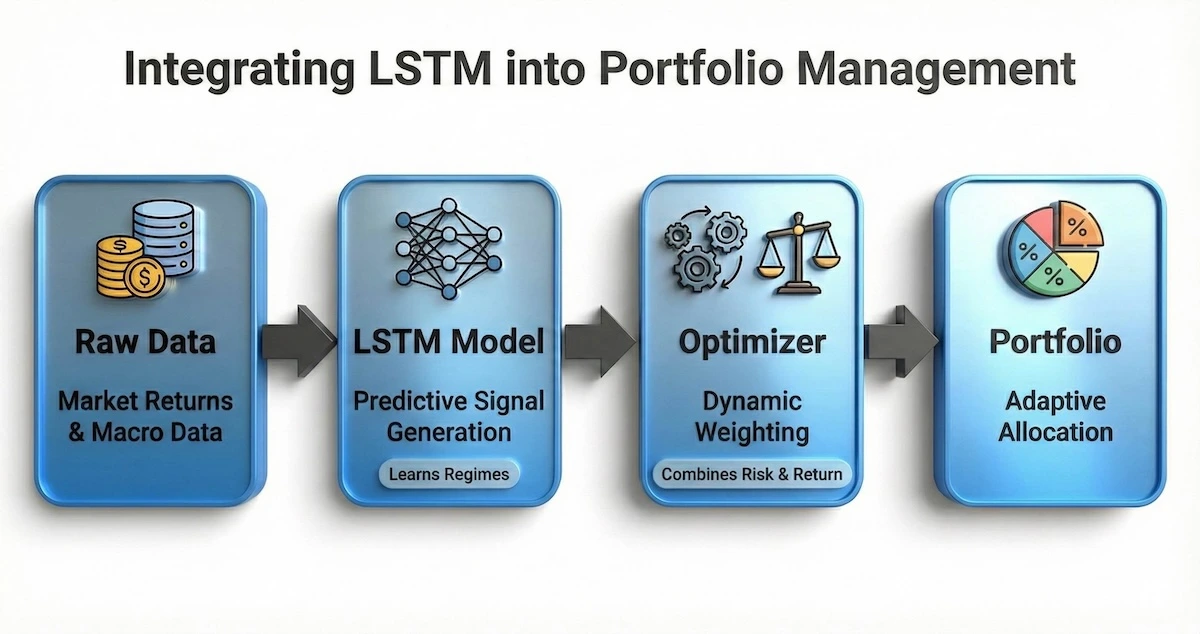
LSTMs do not replace the optimizer; they upgrade the signal that powers it.
Learning non-linear risk structures. Risk is rarely linear. Correlations spike during crises, and volatility clustering can produce long-memory effects. LSTMs can model these effects because they learn patterns that unfold over time instead of reducing everything to a single covariance estimate.
A 2025 study in the Journal of Economic Analysis found that combining LSTM for time-series dynamics with Transformer-based sentiment extraction “improves predictive accuracy relative to standalone models and traditional benchmarks.” The practical lesson: LSTMs handle temporal sequence patterns well; hybrid architectures layer on top of that.
Dr Starke’s research repeatedly shows that when temporal dynamics and predictive signals are combined before optimization, out-of-sample results often improve. These improvements are not guaranteed but tend to appear when models are trained with disciplined validation methods and realistic assumptions.
Those exploring how online platforms support quantitative learning may find this Verbling review covering alternatives, pricing, and offerings a useful reference.
Read More: Top 10 Online Tutoring Websites Worldwide
Why Do LSTMs Often Outperform MVO in Out-of-Sample Testing?
Out-of-sample performance is the only metric that matters in production allocation. In-sample results are available to any model that memorizes the past. The question is whether LSTM-based systems hold up on data the model never saw during training and the 2025–2026 evidence base is increasingly affirmative, with important caveats.
A Research Square preprint (2025) evaluated LSTM on 50 S&P 500 stocks from 2016 to 2024, with rigorous out-of-sample testing from January 2022 to December 2024. The model achieved directional accuracy of 59.3% and delivered a cumulative three-year return of 28.7% versus 22.4% for the equal-weight benchmark. The Sharpe ratio improved by 18% over equal weighting.
Critically, the study also flagged that the strategy underperformed the S&P 500 index over the same period, and that unmodeled transaction costs could reduce returns by approximately one percentage point annually. That honest acknowledgement is exactly the kind of nuance most competing articles skip.
Several structural reasons explain why LSTM-enriched systems outperform classical allocation in out-of-sample conditions.
HRP and HERC reduce estimation error by design. Machine learning-driven allocators like Hierarchical Risk Parity and its extension HERC inherently reduce estimation error by clustering assets and allocating risk more evenly. According to López de Prado’s foundational research, confirmed empirically in multiple 2025 studies HRP improves out-of-sample Sharpe ratios by approximately 31% over Critical Line Algorithm strategies.
HRP never inverts the covariance matrix, which eliminates the primary source of instability in MVO. These methods consistently outperform equal weighting and inverse volatility allocation in empirical studies.
Dynamic inputs produce more robust allocations. The output of an LSTM does not need to be a direct weight. It can be a volatility forecast, a regime indicator, a correlation estimate, or a probability of a drawdown event. Feeding dynamic estimates into an optimizer often produces more robust allocations than feeding static estimates.
A 2026 hybrid framework paper (IRJMS) comparing LSTM, GRU, CNN, and LSTM-CNN on Indian equity data found that LSTM captured long-term patterns well but that hybrid LSTM-CNN improved performance on sequences with both local and global structure a reminder that the architecture choice matters.
Regime awareness changes the risk profile in practice. A key advantage of LSTMs is their ability to recognize when the market mood changes, known as a regime shift. The chart below demonstrates how non-linear models react to volatility spikes that linear models typically miss.
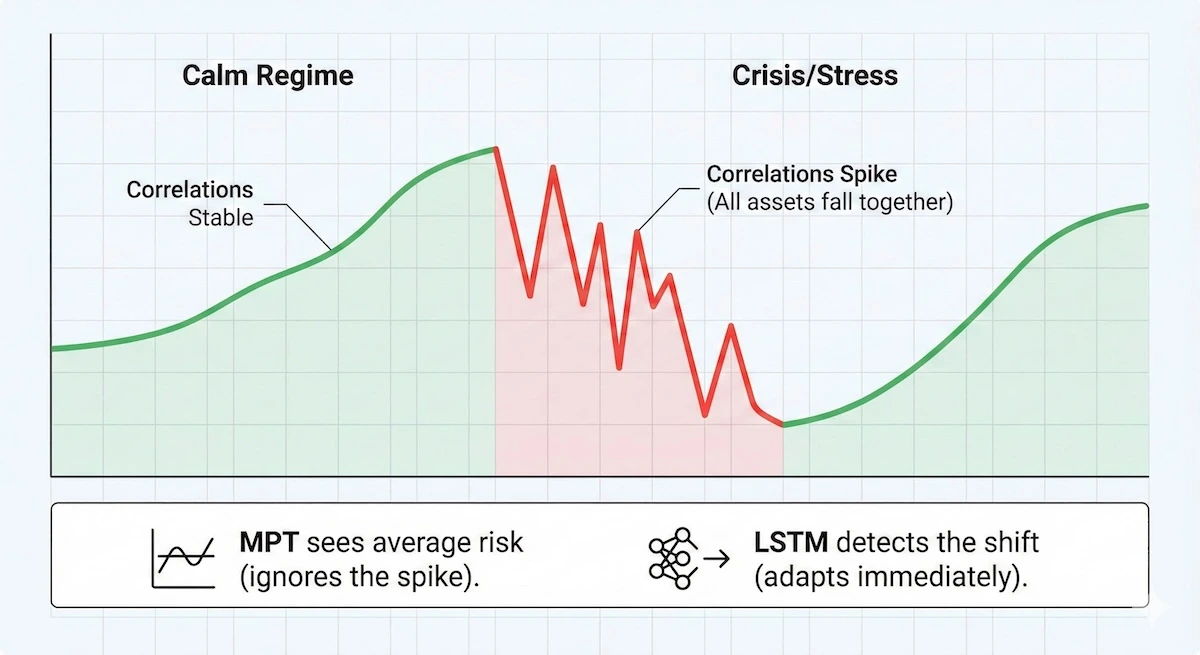
During market stress, correlations spike. LSTMs detect this “regime shift,” whereas traditional models see average noise.
Because LSTMs process sequences, they naturally adjust when markets move from calm to stressed conditions. A classical optimizer has no such memory unless explicitly engineered into the model.
Students interested in how financial data analysis connects to broader investment contexts may benefit from working with an investment banking tutor to understand how portfolio signals translate into real-world decisions.
How Online Tutoring Enhances Test Prep for Standardized Exams
How Do You Build an LSTM Portfolio Model in Python?
Building an LSTM-based portfolio signal in Python is more accessible than most students expect. You do not need a proprietary data feed or a research cluster. What you do need is a disciplined pipeline, careful data handling, and honest evaluation. The following walkthrough demonstrates the core building blocks using TensorFlow/Keras and yfinance for data retrieval two of the most widely used tools in the Python quant stack as of 2026.
A word before the code: the LSTM here generates a return signal used to inform allocation weights. It is not a magic price prediction machine. The signal feeds into an optimizer treat it as an upstream improvement to the inputs, not a standalone trading system.
Step 1: Data Retrieval and Preprocessing
Clean data matters more than network size. Preprocessing directly influences the performance of every downstream step.
import numpy as np
import pandas as pd
import yfinance as yf
from sklearn.preprocessing import MinMaxScaler
# Download multi-asset data
tickers = [‘SPY’, ‘TLT’, ‘GLD’, ‘VNQ’]
raw = yf.download(tickers, start=’2015-01-01′, end=’2024-12-31′)[‘Close’]
# Compute log returns — avoids the persistence problem
log_returns = np.log(raw / raw.shift(1)).dropna()
# Normalise per asset using training window only (prevents leakage)
scaler = MinMaxScaler()
scaled = pd.DataFrame(
scaler.fit_transform(log_returns),
columns=log_returns.columns,
index=log_returns.index
)
Why log returns, not prices? A common mistake is feeding raw closing prices into an LSTM. Price series are non-stationary; they drift upward over time and the LSTM learns to track recent levels rather than forecast genuine movement. This is called the persistence problem. Reducing lag-1 autocorrelation through log return transformation is essential. A 2025 Research Square study showed this single change reduced lag-1 autocorrelation from 0.89 to 0.23 in their framework.
Step 2: Building the Sequence Dataset and LSTM Model
LSTMs require 3D input tensors of shape (samples, time steps, features). A lookback window of 30 to 60 days is a reasonable starting point for daily equity data.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
LOOKBACK = 30
def create_sequences(data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i]) # predict next-period returns
return np.array(X), np.array(y)
X, y = create_sequences(scaled.values, LOOKBACK)
# Chronological split — NEVER shuffle financial time series
split = int(0.75 * len(X))
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# Define the LSTM model
model = Sequential([
LSTM(64, input_shape=(LOOKBACK, X.shape[2]), return_sequences=True),
Dropout(0.2),
LSTM(32),
Dropout(0.2),
Dense(y.shape[1]) # output: one forecast per asset
])
model.compile(optimizer=’adam’, loss=’mean_squared_error’)
model.fit(
X_train, y_train,
epochs=50,
batch_size=32,
validation_split=0.1,
verbose=0
)
A 30-week lookback, 64 hidden units, and 0.2 dropout the configuration used in the 2025 LSTM-PPO hybrid study is a solid baseline. Grid search is inefficient; practitioners typically rely on smarter search methods or Bayesian optimisation over a smaller hyperparameter space.
Step 3: Generating Allocation Weights from LSTM Signals
The LSTM output is a forecast of next-period returns. These predictions feed into a simple allocation scheme here, a signal-scaled inverse-volatility approach. You can replace this with HRP from the pypfopt library for more robust weighting.
from scipy.optimize import minimize
# Generate predictions on test set
preds = model.predict(X_test)
# Simple signal-weighted allocation: long assets with positive predicted return
# Apply softmax to normalise weights to sum to 1
def softmax_weights(signals):
clipped = np.clip(signals, 0, None) # long-only
total = clipped.sum()
if total == 0:
return np.ones(len(signals)) / len(signals)
return clipped / total
weights_series = np.array([softmax_weights(pred) for pred in preds])
# Portfolio returns
actual_returns = log_returns.values[split + LOOKBACK:]
portfolio_returns = (weights_series * actual_returns[:len(weights_series)]).sum(axis=1)
# Key metrics
sharpe = portfolio_returns.mean() / portfolio_returns.std() * np.sqrt(252)
cumulative_return = np.expm1(portfolio_returns.cumsum())[-1]
print(f”Annualised Sharpe: {sharpe:.2f}”)
print(f”Cumulative Return (test period): {cumulative_return:.1%}”)
This is a minimal working pipeline. In a production system you would add walk-forward re-training, transaction cost modeling (preliminary estimates suggest trading friction reduces returns by approximately 1 percentage point annually on monthly-rebalanced systems), and a formal drawdown constraint.
Step 4: Walk-Forward Validation — The Non-Negotiable Step
Walk-forward optimization is not optional it is the difference between a research result and a production system. The core principle: train only on past data, validate on unseen future segments, slide the window forward, repeat.
# Walk-forward evaluation skeleton
window_size = 504 # ~2 years of daily data
step_size = 63 # re-train quarterly
results = []
for start in range(0, len(scaled) – window_size – LOOKBACK, step_size):
train_data = scaled.values[start : start + window_size]
test_data = scaled.values[start + window_size : start + window_size + step_size]
X_wf, y_wf = create_sequences(train_data, LOOKBACK)
# … retrain model on X_wf, y_wf …
# … generate predictions on test_data sequences …
# … compute period metrics, append to results …
pass # replace with actual fit/predict calls
The diagram below illustrates the sliding window process that prevents your model from “seeing the future.”
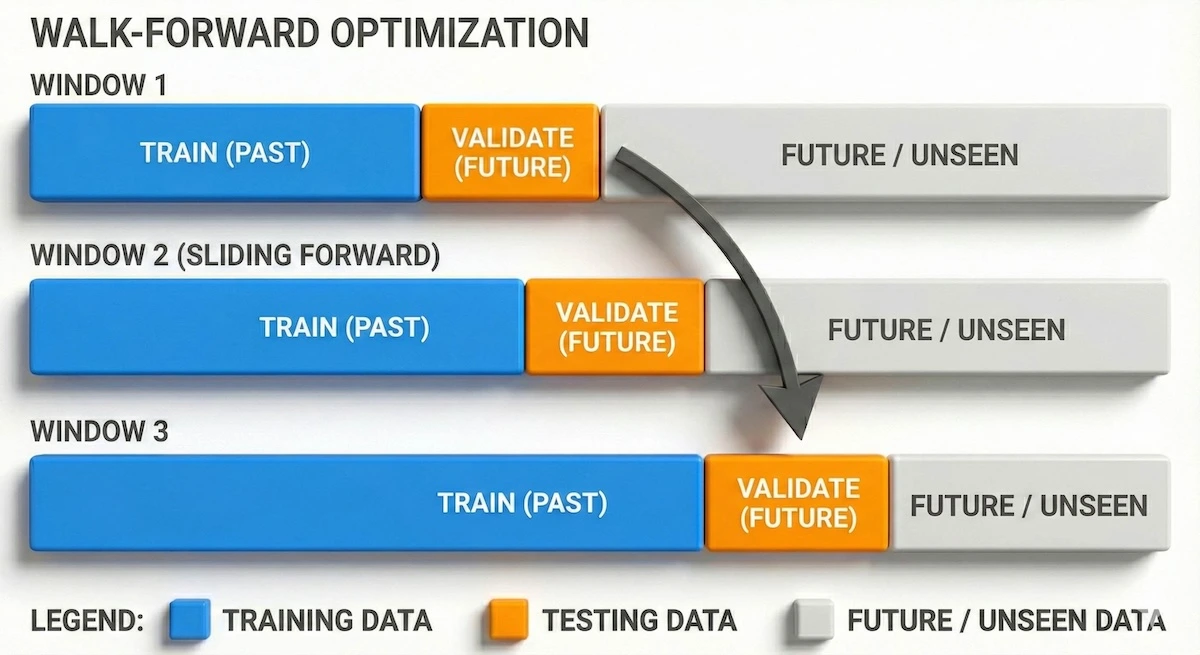
By constantly sliding the training window forward, the model is always tested on unseen data, simulating live trading conditions.
Walk-forward optimization is emphasized heavily in QuantInsti’s AI portfolio management curriculum because it prevents the illusion of perfect equity curves that never survive live trading.
Also Read: 24/7 Premium 1:1 Tutoring For Standardized Tests
What Are the Common Pitfalls When Using LSTMs in Portfolio Models?
LSTMs can perform well, but they also introduce real challenges that a less thorough source would leave unaddressed. Understanding these pitfalls before you build not after a model fails in production is the mark of competent applied work.
Overfitting to history is the dominant failure mode. Financial time series have low signal-to-noise ratios. A model with too many parameters, too long a lookback, or no dropout will simply memorise the training set and fail immediately on live data.
Walk-forward optimization is the primary defence. Dropout (0.2–0.3 is standard), early stopping, and regularisation all help. What does not help: adding more data features without domain justification. As Raimondo Marino’s research noted, preprocessing quality directly influences every downstream step. Advanced quants often apply López de Prado’s fractional differentiation technique to achieve partial stationarity without discarding long-memory information that genuinely improves the signal.
Data quality and feature engineering are upstream determinants. Clean and relevant data matters more than network size. Quants must handle missing values carefully (forward-fill for sparse gaps; drop assets with excessive sparsity), normalise inputs on the training window only to prevent lookahead bias, and select features that genuinely add signal.
Useful features beyond OHLCV include 1–5 day log returns, EWMA volatility with α ≈ 0.94, market regime hints (e.g., SPY 20/60-day slopes), and RSI or Bollinger Band indicators. Add features only after the base environment behaves correctly isolating effects is how you know what is actually working.
Hyperparameter tuning requires systematic approach, not guesswork. LSTMs have many tunable components: number of layers, hidden units, dropout rate, lookback window, learning rate, and batch size. Grid search is computationally unrealistic for financial time series.
Practitioners rely on Bayesian optimisation or random search with a smaller hyperparameter space. These tuning processes should be repeated across multiple walk-forward windows to ensure robustness a configuration that works in one market regime does not necessarily generalise across all of them.
For students exploring how tutoring platforms support quantitative and analytical learning, this BookNook review covering alternatives, pricing, and offerings provides a useful comparison of structured learning tools.
How Does LSTM Compare to Transformer Models for Portfolio Use?
This is the question that experienced quants are now asking, and the answer in 2026 is more nuanced than the headline claims suggest. Transformers are not automatically better than LSTMs for financial time series.
A ScienceDirect study (2025) comparing LSTM, Transformer, ARIMA, and VAR on S&P 500 data from 2015 to 2020 found Transformers achieved an RMSE of 41.87 against LSTM’s 43.25 a modest advantage. Critically, the paper noted that LSTM “provides an optimal balance between performance and computational efficiency,” and that both deep learning approaches “significantly outperform traditional econometric methods, with LSTM achieving a 53.3% reduction in RMSE compared to ARIMA models.”
The practical comparison table below captures what matters for allocation decisions:
| Dimension | LSTM | Transformer |
| Sequential memory | Native (gated cell state) | Learned via attention |
| Differential predictions (returns) | Consistently strong | Marginal advantage only |
| Computational cost | Moderate | High (scales with sequence length) |
| Overfitting risk | Moderate (manageable with dropout) | Higher (more parameters) |
| Interpretability | Low (black-box) | Low–Moderate (attention weights) |
| Production maturity for finance | High (extensive tooling) | Growing (newer deployment patterns) |
| Best for | Daily/weekly return forecasting, regime detection | Sentiment integration, multi-modal inputs |
The emerging consensus in 2026: for pure return-sequence forecasting and regime detection in daily allocation, LSTMs remain the practical default.
Learners comparing study platforms for quantitative subjects may find this Quizlet review covering alternatives, pricing, and offerings helpful when evaluating tools for technical self-study.
Read More: StudyX Online Tutoring Review: Features, Pricing, and Alternatives
What Do Students Most Often Get Wrong About LSTM-Based Allocation?
The most persistent misconceptions worth addressing directly before you build your first model.
Bringing It All Together
When integrated properly, LSTMs and modern optimization techniques create a more adaptive allocation framework. This does not replace financial intuition; instead, it builds on it. Quants can combine predictive signals, dynamic volatility estimates, and stability-driven allocators like HRP to build portfolios that respond more naturally to changing conditions.
For hands-on code, example notebooks, and practical walkthroughs that mirror the workflows discussed here, visit the My Engineering Buddy website. Those resources, including LSTM pipelines, walk-forward scripts, and HRP implementations, are designed to help you translate theory into production-ready experiments.
Students writing up quantitative research findings may also find this IvyPanda review covering alternatives, pricing, and offerings useful when evaluating academic writing support tools.
Frequently Asked Questions: LSTM Models in Portfolio Optimization
Do LSTM models actually predict stock prices accurately?
LSTM models do not predict stock prices accurately in the way most beginners expect. A 2025 peer-reviewed study found that an LSTM trained on 50 S&P 500 stocks achieved directional accuracy of 59.3% meaningful, but far from certain. The value of LSTMs in portfolio management is not that they predict prices precisely. It is that even modest accuracy improvements in the upstream signal produce measurable improvements at the portfolio level: the 2025 study cited an 18% Sharpe ratio improvement over equal weighting from those modest prediction gains. Directional accuracy above 55% applied systematically across many assets with proper risk weighting is operationally useful.
What is the minimum dataset size needed to train an LSTM for portfolio use?
There is no universal minimum, but practitioners commonly use at least five years of daily data for the training window. A 2025 Springer study on HRP estimation windows found that five years of daily data produced the best out-of-sample Sharpe ratio in their framework. For LSTM training, less data increases overfitting risk significantly. Assets with fewer than two to three years of clean history should be excluded or treated with additional regularisation.
Is an LSTM better than a GRU for portfolio applications?
Whether an LSTM is better than a GRU for portfolio applications depends on the sequence structure. GRU (Gated Recurrent Unit) is a streamlined variant of LSTM that merges the input and forget gates into a single update gate. For short sequences and simpler patterns, GRU often performs comparably to LSTM with fewer parameters and faster training. A 2026 comparative study (IRJMS) found that each model has “its own strengths and limitations in learning short- and long-term patterns.” The practical recommendation: start with LSTM for its established track record and deeper tooling support; test GRU as an ablation if training time is a constraint.
Can LSTMs be used for crypto or commodity portfolios, not just equities?
Yes, LSTMs can be used for crypto or commodity portfolios, and the architecture transfers well. A 2025 hybrid LSTM-PPO study applied the framework to a multi-asset universe including US equities, Indonesian equities, government bonds, and cryptocurrencies, evaluating performance across all four classes. The study used a 30-week lookback, 64 hidden units, and 0.2 dropout the same configuration that works for equity portfolios.
How often should an LSTM portfolio model be retrained?
Quarterly re-training is the most common practice among production quants. The 2025 PPO-LSTM study used 70% training and 30% testing with strict chronological ordering. Walk-forward approaches retrain every step size commonly 63 trading days (one quarter). Monthly rebalancing paired with quarterly re-training balances freshness of the model against computational cost.
What Python libraries are most commonly used to build LSTM portfolio models in 2026?
The standard stack for building LSTM portfolio models in 2026 is TensorFlow/Keras or PyTorch for the LSTM model itself, yfinance or Bloomberg API for data retrieval, pandas and NumPy for preprocessing, scikit-learn for normalisation and evaluation metrics, and pypfopt for HRP or MVO-based allocation once LSTM signals are generated. TensorFlow’s Keras API is the most documented for finance applications. PyTorch is preferred in research settings for its flexibility. The pypfopt library provides clean implementations of HRP, HERC, and MVO that integrate directly with LSTM signal outputs.
Conclusion
Markets have evolved beyond the static assumptions that shaped early portfolio theory. While MVO remains an important foundation, its limitations are clear in any environment where correlations shift and volatility regimes change which is consistently the case in 2026. LSTMs offer a way to incorporate temporal patterns, non-linear relationships, and predictive signals directly into the allocation pipeline.
A growing body of 2025–2026 research confirms measurable out-of-sample improvements: 18% Sharpe improvement over equal weighting, 31% better out-of-sample variance than CLA when combined with HRP, and consistent outperformance of ARIMA baselines by 53% or more on RMSE.
Related Reading
******************************
This article provides general educational guidance only. It is NOT official exam policy, professional academic advice, or guaranteed results. Always verify information with your school, official exam boards (College Board, Cambridge, IB), or qualified professionals before making decisions. Read Full Policies & Disclaimer , Contact Us To Report An Error